DURITO
General Proposal - 8 May, 2001
Table of Contents
- Summary
- General Design
- XML and Structural Encoding
- Resource Description, Classes, and RDF
- Searches
- Durito in Two Acts
- Components Found and to Be Found
- Immediate Tasks
- ...Regarding the Name
- References
Summary
This is a proposal for the creation of an open-source application that will manage, display and analyse various kinds of documents in a diversity of environments. The idea of creating Durito arose during work on an academic project that aims to digitize historical documents from the Mexican Revolution. Called "Testimonios Zapatistas" (TZ), the project will publish the digitized material via Internet and CD-ROM, and will need an application that can serve as intermediary between static documents and end users. Durito's first goal will be to achieve the functionality required by TZ in its current phase. However, from the outset the program should be designed with more general objectives in mind, so as to be adaptable to future stages of TZ as well as other similar endeavours. Central to Durito's operation will be technologies such as XML and RDF, both cornerstones of the World Wide Web Consortium's proposal to create a Semantic Web.
Durito will be less an independent application than an assembly of already existing components, all of which should be available under open source licenses. Most of the code will be of the "glue" type, in that it will mainly serve to link obtained modules.
The application will be portable; at the very least, it should function under Linux and Windows operating systems. However, our first concern will be to achieve a reasonable degree of stability under Windows. Unless someone convinces us to do otherwise, we will write Durito in Perl.
General Design
For portability (between network and local configurations) Durito will communicate with the end user via a web browser. It will supply data to the browser, which will return the user's requests.
(In the following diagrams, the arrows indicate communication channels or transfer of information.)
Figure 1: Local configuration
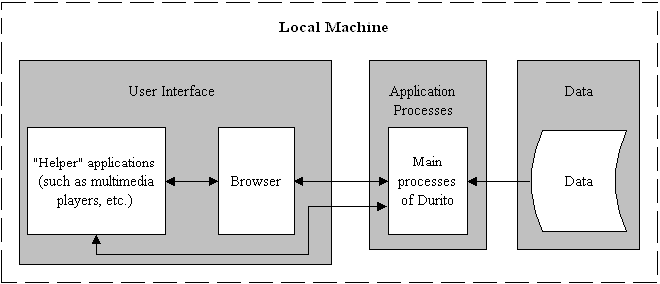
Figure 2: Network configuration
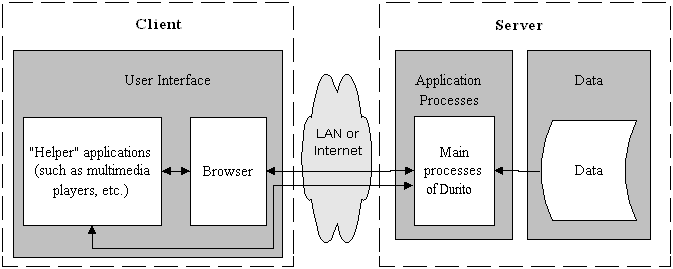
The data layer will contain the documents that the system must manage, associated style sheets (see "XML and Structural Coding"), associated descriptions (see "Resource Description, Classes, and RDF"), generated data (such as indexes of words contained in the documents), and elements of the user interface (screen templates and images for buttons, for example).
The "main processes of Durito" will involve, essentially, the transformation and assembly of elements from the data layer, as per user requests. The functions to be implemented in the first versions are: presentation of a table of contents, presentation of complete documents, and searches.
The program should be compatible with any moderately current and commonplace browser (Netscape 4 or higher, or MSIE4 or higher).
Evidently, there is nothing unusual about this design. Of course, we shouldn't dismiss the possibility of allowing, in future versions, configurations that are more complex. For example, in many situations, it will be useful to locate elements of the data layer in various machines throughout a network.
XML and Structural Encoding
TZ and Durito employ (or will employ) "structural encoding" to process documents. This means that documents contain codes that signal elements of their structure, rather than their format. The benefits of structural encoding include: a superior separation between content and presentation, and greater automation in content analysis.
The text documents being processed by TZ use an implementation of XML defined by the Text Encoding Initiative, an academic project that proposes standards for the encoding of electronic texts and is associated mainly with research in the humanities and social disciplines. Each type of XML document processed by TZ has a related XSLT style sheet, which translates the resource into HTML.
We'll illustrate this briefly. In transcriptions of interviews, a normal practice is to indicate who is speaking by inserting the person's initials before his or her utterance:
Example 1
LT. Zapata fue un hombre dócil.
RT. No me digas.
Instead, TZ uses XML tags to indicate who is speaking:
Example 2
<u who='LT'>Zapata fue un hombre dócil.</u>
<u who='RT'>No me digas.</u>
An XSLT parser can read an XML document, transform it and convert it to HTML in the manner set out by an XSLT style sheet; in TZ, the XML resources must be modified to be more easily understood by human readers. One of the transformations performed by TZ's XSLT style sheets is to replace the utterance tags (Example 2) with plain initials (Example 1). As mentioned, the resources end up as HTML.
In this system, the XML document remains the document of reference. Thus, it will be simple to modify the presentation of all interviews, should the need arise. An additional advantage is that the program will be able to identify which words were spoken by whom--an important facility which should increase the power of search engines as well as other tools that perform automatic analyses.
A detailed description of the structural encoding scheme (or "mark-up" scheme) proposed by TZ is available at our web site.
Though at first Durito will use only TZ's encoding schemes, the program should be designed to be flexible--that is, it should also be compatible with very different formats, including those which neither are XML nor employ structural encoding.
Resource Description, Classes, and RDF
Another basic mechanism for achieving intelligent resource management will be the coherent and general description of documents and their encoding schemes. Here, we go beyond structural encoding of texts, and introduce the encoding of structures and concepts that link resources to each other and to functions of the program.
This part of our proposal has not been extensively tested by other applications. Nor is it essential in order to achieve the minimum functionality needed in the short term. However, it's the most noteworthy element of the design.
As a starting point, let's consider an obvious need: that of creating links between documents. In TZ, for example, an interview will consist of two files: the audio (MP3 or possibly OGG) and the transcription (XML). In addition, it will be necessary to associate the XML file with one or more XSLT style sheets. And there should be paths between the interview and other resources (such as its summary, the description of the project that generated it, the interviewee's biographical data, etc.). Links à la hypertext would be too rigid for this task, and wouldn't take into account the complex of notions that give rise to such connections.
This same concern is at the root of object oriented programming: how, one asks, can one build a logical structure that is at once functional, compact, general, and rich in meaning (and therefore flexible)?
The proposed solution: a system of descriptions and properties, organized in classes. This will be implemented using RDF, a flexible language defined by the World Wide Web Consortium, for storing and manipulating metadata.
We'll explain some of the possibilities that RDF opens up. Let's set aside for the moment TZ's collection, and imagine a different one, which contains two general kinds of resource: interviews and written documents. For all resources, we have: catalogue information (that is, author, title of the work, etc.), a summary, and a transcription; in addition, for each interview, we have an audio recording, and for each written document, there is a scanned image.
RDF helps us describe this collection. To begin with, it provides a mechanism for linking all four components of each resource, such that the connections contain the necessary semantic information. For example: both interviews and written documents have summaries; with RDF, one can create a single "property" called "summary" and use it to link all synopses to the appropriate full documents.
This structure allows the program to recognize what is a summary and what isn't, and modify its behaviour accordingly. When the user is viewing (or hearing) a resource (interview or written document) that has an associated synopsis, the program can display a link to it. The search engine can give priority to words found in summaries. Or carry out searches only within them. Or generate a list of them. And so on. This flexibility is preserved even if we add other kinds of documents to the collection, provided that everything that is a summary is associated with the same property.
Now, let's extend the model by adding the concept of classes of properties. This will allow us to organize properties hierarchically in groups and sub-groups, with inherited functionalities.
We might create one taxonomy to distinguish between a summary, a file containing catalogue information, and a full representation of a resource. Another taxonomy might include the following categories: image, audio, and text. This last class could contain sub-classes: plain text and marked-up (structurally encoded) text, which, in turn, could be subdivided into classifications that refer to the various mark-up schemes used by available encoded text documents.
Figure 3: A few possible taxonomies
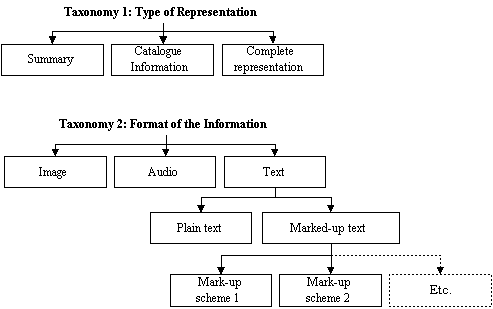
This model gives way to many possibilities. For example, it would be simple to make the program generate the list of all resources (interviews and written documents) without going into detail: it would just review everything associated with the property "catalogue information". Though it could also produce a more complete table of contents that would display all representations available for each resource. The search engine would know what is text and what isn't. These are just a few of the functions that this methodology would facilitate.
It would be important to include, as described above, a mechanism for recording which XML mark-up scheme is used by each resource. Why? Well, let's suppose that each kind of document (interview transcription, written document transcription, interview summary, written document summary, catalogue information of interviews, catalogue information of written documents) was elaborated using a different XML structural mark-up scheme. I'm not using the term "DTD" or "Schema" because what differentiates mark-up systems tends to go beyond syntax; rather, I'm referring to the concepts that motivate the use of syntaxes. An extreme case would be two documents that share the same DTD but whose authors used different criteria during the encoding process.
Many of Durito's functions could well make use of information on encoding schemes. For example, the search engine could provide the option of searching only within certain key parts of a resource's XML structure. Let's consider the case of a group of documents that use the tag <placeName> to indicate toponyms. It would be useful to be able to search only within place names--in this case, within the contents of <placeName> tags. But what if another type of document uses a different tag--say, <placeNamingWord>--for the same purpose? If the program can identify the encoding schemes of these resources and is aware of the mechanism that each employs to indicate toponyms, it can effectively and transparently perform the search in both types of document.
In the long term, it will likely be worthwhile to employ this kind of system of descriptions and properties to represent not only relationships between resources but also significant aspects of structural mark-up schemes. Thus, the added functionality provided by structural encoding should remain available even when dissimilar encoding schemes are employed. In order to create "bridges" between schemes, we could "teach" the program certain concepts, such as: time, geographical location, people, bibliographic references, etc. (I expect that techniques developed in the field of artificial intelligence would be of use here.)
I hope that, after reviewing this section, the reader has obtained at least a general idea of the approach I'd like to use. So...there you have it. Durito should function with, or should be configurable to function with, this kind of model.
Searches
Search engines are among the most important tools that computers can make available to text-based research.
Durito should be able to perform several kinds of searches and take into account a wide variety of parameters while doing so. To begin with, the search engine should consider features of a text's natural language: when a user searches for "ir" (Spanish for "to go"), the results should also include "va" ("goes"), "fue" ("went"), etc. The program will have to recognize the equivalence of various forms of any given verb, adjective or noun. (In fact, we've already found an open-source component that can conjugate Spanish verbs.) Also, we'd like to make the program able to search using synonyms--such that "crop" also finds "harvest", for example. (What, aren't there any open content Spanish synonym dictionaries out there? Ah...)
As mentioned, Durito should take into account elements of documents' structural mark-up. It will provide users with the option of searching within different parts of the mark-up. In some cases, searches within elements of the encoding should automatically be combined with other simpler types of searches. For example, some documents will likely use XML tags to relate subject information to parts of the text. A search for "campesino" (peasant) could simultaneously look for occurrences of this word in the text, others derived from the same root, synonyms, and tags which signal "campesinos" as the subject of a section of text--according greater priority to matching subject information.
The program will provide a simple search option (in which mechanisms like the one we've just described will function transparently) and an advanced option (in which the user will have full control over such mechanisms and will be able to define composite searches).
We should allow users to search for a word within a given distance from another word, or for several words within a single XML tag.
We will need to find (or create) a language to define complex search requests. There are a few conventions that are more or less shared among Web search engines; we're also aware of a language used by DynaBase, a program with some functions that are similar to those of Durito.
The search engine will have to generate an index of all the words contained in the collection; it will do this as part of the process of configuration and integration, before the documents are provided to users (see below, "Durito in Two Acts"). The index will contain information on the location in the XML structure of every occurrence of every word. While we know of several search engines that are available under open source licenses, we haven't yet found one that can work with XML in this manner.
Durito in Two Acts
There are two general processes which Durito must manage. First, it will set up the collection. This will involve configuring Durito, adding documents and their RDF descriptions, and creating automatically generated documents such as the word index to be used by the search engine. This process will not be carried out via a browser, though someday we might build a friendly GUI interface for it.
The second process will involve the presentation and analysis of the documents; this is the phase that we've been discussing throughout this text.
It is important to note that we don't propose to make Durito an XML or XSLT editor. Documents, mark-up schemes and styles sheets will have to be designed and created using other applications.
Minimum Functionality Required for TZ
The current phase of the "Testimonios Zapatistas" project (TZ) entails the creation of a prototype of the electronic, publishable version of the collection it is preparing. The prototype will be available on CD-ROM or via Internet and will contain approximately 15 interviews (audio and text) as well as a few written documents, including interview summaries. Users must be able to:
- view the list of interviews and written documents contained in the prototype;
- view the complete text of an interview or document;
- listen to the complete or partial audio of an interview while the text automatically scrolls in sync;
- listen to the audio of an interview as of a specific point, which the user indicates in the text;
- search for words contained in interviews and documents, more or less in the manner of Web search engines.
Components Found and to Be Found
To enable Durito to communicate with a Web browser: in a network configuration, we'll use the Apache web server. The local configuration might use Apache as well. (See "Immediate Tasks".)
XSLT Parser: Sablotron, from the Ginger Alliance, looks useful.
XQuery, XML-QL or XQL engine (or something similar): we haven't determined whether we'll need one of these, but we probably will.
RDF and RDF Schema parser: have yet to choose one.
For communication between Durito and the data layer: there is an application which might be useful here: Charlie, also from the Ginger Alliance.
Search Engine: we have yet to choose one. (It must be "XML-aware" and allow complex searches.)
Natural language components: for conjugating Spanish verbs, there's the compjugador. For all other parts of Spanish and for other languages, we have naught.
Synonyms: we haven't found a Spanish synonym dictionary, nor do we have a software component that would manage one.
MP3 player: it might be necessary to distribute one of these with Durito; several are free.
Immediate Tasks
Our very long to-do list includes:
- elaborating an RDF Schema and descriptions in terms of TZ's concrete needs, as explained in "Resource Description, Classes, and RDF";
- researching languages for defining searches in text resources;
- determining whether it's a good idea to use Apache for local configurations (could that compromise the machine's security?);
- figuring out the nitty-gritty of the program's interaction with the MP3 player; and
- determining which of the multiple flavours of open source licenses suits our needs.
...Regarding the Name
In addition to being the acronym of a phrase that perfectly describes this project, "Durito" is the name of a famous rebellious beetle.